이상치 처리하기
이상치가 존재하는 데이터를 머신러닝에 사용하게 된다면 성능 저하를 야기할 수 있습니다. 그렇기에 데이터 전 처리 과정에서는 이상치를 판별하고 처리합니다.
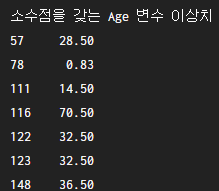
이번 실습에서는 titanic 데이터에서 Age 변수에 존재하는 이상치를 제거합니다. 아래 그림과 같이 Age 변수 안에는 소수점으로 표현되는 데이터가 존재합니다. 나이는 자연수로 표현되어야 하기에 이러한 소수점 데이터는 이상치로 판단하고 삭제하도록 합니다.

titanic 데이터 구성

지시사항
- Age 변수에서 outlier 에 있는 이상치를 제외한 데이터를 titanic_3에 저장합니다.
import pandas as pd
import numpy as np
# 데이터를 읽어옵니다.
titanic = pd.read_csv('./data/titanic.csv')
# Cabin 변수를 제거합니다.
titanic_1 = titanic.drop(columns=['Cabin'])
# 결측값이 존재하는 샘플 제거합니다.
titanic_2 = titanic_1.dropna()
# (Age 값 - 내림 Age 값) 0 보다 크다면 소수점을 갖는 데이터로 분류합니다.
outlier = titanic_2[titanic_2['Age']-np.floor(titanic_2['Age']) > 0 ]['Age']
print('소수점을 갖는 Age 변수 이상치')
print(outlier)
print('이상치 처리 전 샘플 개수: %d' %(len(titanic_2)))
print('이상치 개수: %d' %(len(outlier)))
"""
1. 이상치를 처리합니다
-> np.floor() 를 사용하면 입력값의 소수점을 제외한 정수 부분을 얻을 수 있습니다.
-> titanic_2['Age'] 에서 np.floor(titanic_2['Age']) 을 뺀 값이 0이면 정수입니다.
-> 즉, titanic_2 에서 titanic_2['Age']-np.floor(titanic_2['Age']) 값이 0 인 샘플만 titanic_3에 저장합니다.
"""
titanic_3 = titanic_2[titanic_2['Age']-np.floor(titanic_2['Age']) == 0 ] # _ 안을 채우세요.
print('이상치 처리 후 샘플 개수: %d' %(len(titanic_3)))
이상치 처리하기
이상치가 존재하는 데이터를 머신러닝에 사용하게 된다면 성능 저하를 야기할 수 있습니다. 그렇기에 데이터 전 처리 과정에서는 이상치를 판별하고 처리합니다.
이번 실습에서는 titanic 데이터에서 Age 변수에 존재하는 이상치를 제거합니다. 아래 그림과 같이 Age 변수 안에는 소수점으로 표현되는 데이터가 존재합니다. 나이는 자연수로 표현되어야 하기에 이러한 소수점 데이터는 이상치로 판단하고 삭제하도록 합니다.
titanic 데이터 구성

지시사항
- Age 변수에서 outlier 에 있는 이상치를 제외한 데이터를 titanic_3에 저장합니다.
'ML' 카테고리의 다른 글
| 단순 선형 회귀 분석하기 (0) | 2022.11.23 |
|---|---|
| 단순 선형 회귀 분석하기 - 데이터 전 처리 (0) | 2022.11.22 |
| 데이터분리하기 train_test_split (0) | 2022.11.22 |
| 수치형 자료 변환하기 - 표준화 (0) | 2022.11.22 |
| 수치형 자료 변환하기 - 정규화 (0) | 2022.11.22 |